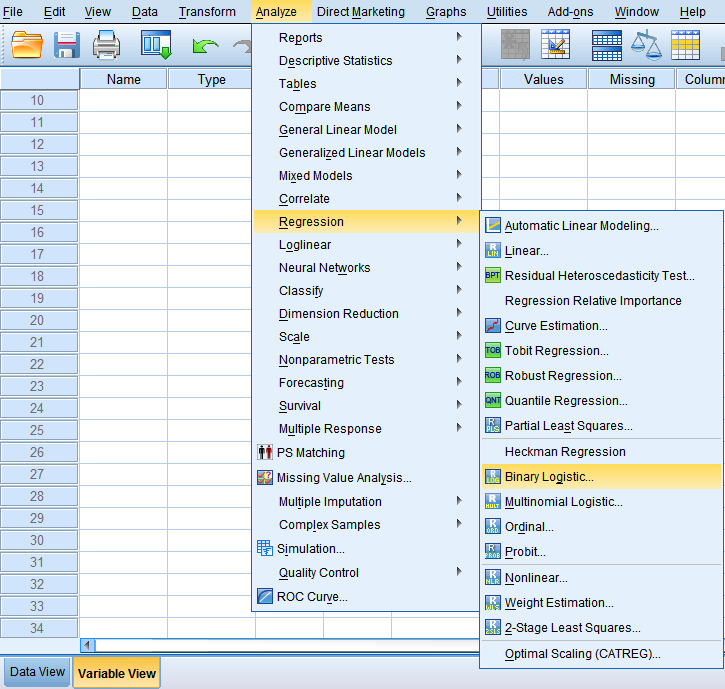
SPSS实战:回归中哑变量的设置和结果解读
2018-11-07 医咖会 医咖会
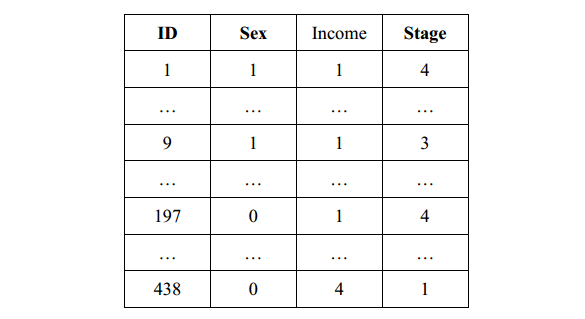
在构建回归模型时,如果自变量X为连续性变量,回归系数β可以解释为:在其他自变量不变的条件下,X每改变一个单位,所引起的因变量Y的平均变化量;如果自变量X为二分类变量,例如是否饮酒(1=是,0=否),则回归系数β可以解释为:其他自变量不变的条件下,X=1(饮酒者)与X=0(不饮酒者)相比,所引起的因变量Y的平均变化量。 但是,当自变量X为多分类变量时,例如职业、学历、血型、疾病严重程度等等,此
在构建回归模型时,如果自变量X为连续性变量,回归系数β可以解释为:在其他自变量不变的条件下,X每改变一个单位,所引起的因变量Y的平均变化量;如果自变量X为二分类变量,例如是否饮酒(1=是,0=否),则回归系数β可以解释为:其他自变量不变的条件下,X=1(饮酒者)与X=0(不饮酒者)相比,所引起的因变量Y的平均变化量。 但是,当自变量X为多分类变量时,例如职业、学历、血型、疾病严重程度等等,此时仅用一个回归系数来解释多分类变量之间的变化关系,及其对因变量的影响,就显得太不理想。 此时,我们通常会将原始的多分类变量转化为哑变量,每个哑变量只代表某两个级别或若干个级别间的差异,通过构建回归模型,每一个哑变量都能得出一个估计的回归系数,从而使得回归的结果更易于解释,更具有实际意义。 哑变量 哑变量(Dummy Variable),又称为虚拟变量、虚设变量或名义变量,从名称上看就知道,它是人为虚设的变量,通常取值为0或1,来反映某个变量的不同属性。对于有n个分类属性的自变量,通常需要选取1个分类作为参照,因此可以产生n-1个哑变量。 将哑变量引入回归模型,虽然使模型变得较为复杂,但可以更直观地反
作者:医咖会
版权声明:
本网站所有注明“来源:梅斯医学”或“来源:MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明“来源:梅斯医学”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言
小提示:本篇资讯需要登录阅读,点击跳转登录



写得好
116
很直观,一直在用SPSS
113
感谢小编为我们准备了如此丰盛的精神大餐,同时也向作者致谢!认真学习了,点赞!
120