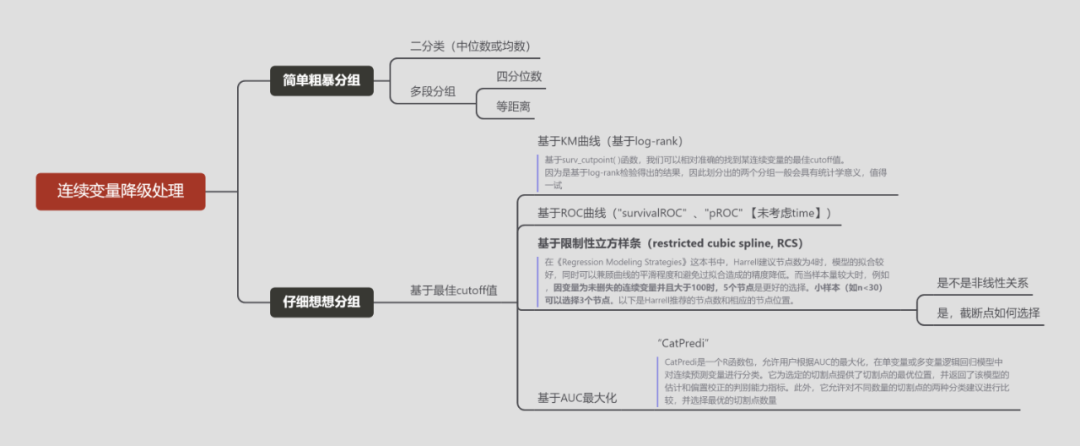
在临床预测模型的构建中,为了让模型有更好的适用性和简便性,许多研究人员将连续型自变量转换为分类变量。 降级处理的首要原因是为了在临床实践中“分类”的变量简单判别,使预测模型的结果更实用;其次,clinical prediction rules(CPRs)中分类变量广泛应用,在模型整体表现最优的基础上,一个模型的适用性取决于变量是否简单易判。 从纯统计的角度看,将连续变量降级处理为分类变量会导致信息的丢失与模型预测能力的降低。但是从临床角度看,如果预测因子是分类的,更容易快速的对患者进行结局的判定。此外,当前多数预测模型都假设Y与X之间是线性关系,但是若两者不服从该假设,那么构建的模型真实性就值得怀疑。 我们对常见的几种降级处理方式进行了总结。 各种方法特点总结如下: 方法 特点 推荐性 二分法 简单粗暴 馊主意 多分类 3、4或5个类别可捕获更多的预后信息,但它们不流畅,对切点的选择敏感且不稳 不推荐,解释不清楚 多项式 添加二次项、立方项 可检查非线性关系,但是不稳定 变换 对数、平方根、逆 可以提供可靠的非线性总结 分段多项式(FP) 多项式灵
作者:杨弘
版权声明:
本网站所有注明“来源:梅斯医学”或“来源:MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明“来源:梅斯医学”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言
小提示:本篇资讯需要登录阅读,点击跳转登录





历害
58
#连续变量#
28
#预测模型#
43
赞赞赞
74
梅斯里提供了很多疾病的模型计算公式,赞一个!
61