Logistic回归、决策树和支持向量机介绍
2015-12-02 赵屹华 CSDN
分类问题是我们在各个行业的商业业务中遇到的主要问题之一。在本文中,我们将从众多技术中挑选出三种主要技术展开讨论,逻辑回归(Logistic Regression)、决策树(Decision Trees)和支持向量机(Support Vector Machine,SVM)。 上面列出的算法都是用来解决分类问题(SVM和DT也被用于回归,但这不在我们的讨论范围
分类问题是我们在各个行业的商业业务中遇到的主要问题之一。在本文中,我们将从众多技术中挑选出三种主要技术展开讨论,Logistic回归(Logistic Regression)、决策树(Decision Trees)和支持向量机(Support Vector Machine,SVM)。
上面列出的算法都是用来解决分类问题(SVM和DT也被用于回归,但这不在我们的讨论范围之内)。我多次看到有人提问,对于他的问题应该选择哪一种方法。经典的也是最正确的回答是“看情况而定!”,这样的回答却不能让提问者满意。确实让人很费神。因此,我决定谈一谈究竟是看什么情况而定。
这个解释是基于非常简化的二维问题,但足以借此来理解读者棘手的更高维度数据。
我将从最重要的问题开始讨论:在分类问题中我们究竟要做什么?显然,我们是要做分类。(这是个严肃的问题?真的吗?)我再来复述一遍吧。为了做分类,我们试图寻找决策边界线或是一条曲线(不必是直线),在特征空间里区分两个类别。
特征空间这个词听起来非常高大上,容易让很多新人犯迷糊。我给你展示一个例子来解释吧。我有一个样本,它包含三个变量:x1, x2和target。target有0和1两种值,取决于预测变量x1和x2的值。我将数据绘制在坐标轴上。
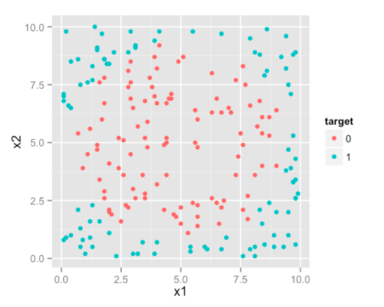
这就是特征空间,观测值分布于其中。这里因为我们只有两个预测变量/特征,所有特征空间是二维的。你会发现两个类别的样本用不同颜色的点做了标记。我希望我们的算法能计算出一条直线/曲线来分离这个类别。
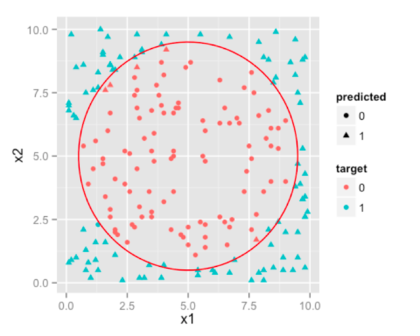
通过目测可知,理想的决策边界(分割曲线)是一个圆。实际决策边界形状的差异则是由于Logistic回归、决策树和支持向量机算法的差异引起的。
先说逻辑回归。很多人对逻辑回归的决策边界都有误解。这种误解是由于大多数时候提到Logistic回归,人们就见到那条著名的S型曲线。
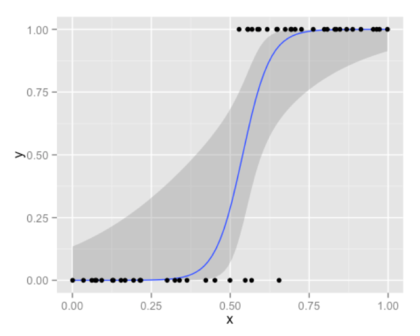
上图所示的蓝色曲线并不是决策边界。它是Logistic回归模型的二元响应的一种变形。Logistic回归的决策边界总是一条直线(或者一个平面,在更高维度上是超平面)。让你信服的最好方法,就是展示出大家都熟知的Logistic回归方程式。
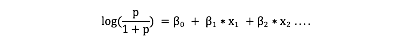
我们做一个简单的假设,F是所有预测变量的线性组合。

上面的等式也可以写作:

当你进行预测的时候,对概率值做一个分数截断,高于截断值的概率为1,否则为0。假设截断值用c表示,那么决策过程就变成了这样:
Y=1 if p>c, 否则0。最后给出的决策边界是F>常数。
F>常数,无非就是一个线性决策边界。我们样本数据用逻辑回归得到的结果将会是这样。
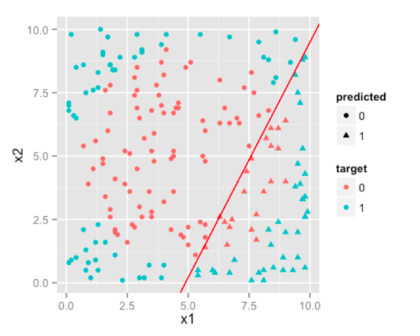
你会发现效果并不好。因为无论你怎么做,逻辑回归方法得到的决策边界总是线性的,并不能得到这里需要的环状边界。因此,Logistic回归适用于处理接近线性可分的分类问题。(虽然可以对变量做变换得到线性可分的结果,但我们在此不讨论这类情况。)
接着我们来看决策树如何处理这类问题。我们都知道决策树是按照层次结构的规则生成的。以我们的数据为例。

如果你仔细思考,这些决策规则x2 || const OR x1 || const 只是用平行于轴线的直线将特征空间切分,如下图所示。

我们可以通过增加树的大小使它生长得更复杂,用越来越多的分区来模拟环状边界。

哈哈!趋向于环状了,很不错。如果你继续增加树的尺寸,你会注意到决策边界会不断地用平行线围成一个环状区域。因此,如果边界是非线性的,并且能通过不断将特征空间切分为矩形来模拟,那么决策树是比Logistic回归更好的选择。
然后我们再来看看SVM的结果。SVM通过把你的特征空间映射到核空间,使得各个类别线性可分。这个过程更简单的解释就是SVM给特征空间又额外增加了一个维度,使得类别线性可分。这个决策边界映射回原特征空间后得到的是非线性决策边界。下图比我的解释更清楚。
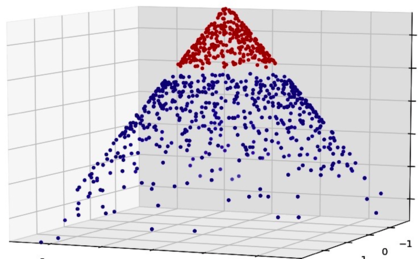
你可以看到,一旦样本数据以某种方式增加了一个维度,我们就能用一个平面来分割数据(线性分类器),这个平面映射回原来的二维特征空间,就能得到一个环状的决策边界。
SVM在我们数据集上的效果多棒啊:
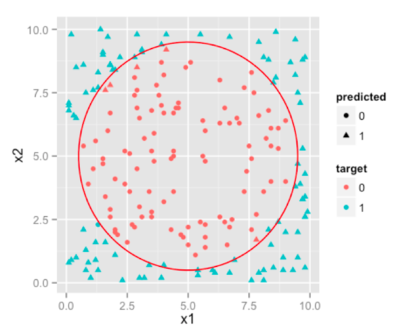
注:决策边界并不是这么标准的圆形,但是非常接近了(可能是多边形)。我们为了操作简便,就用圆环代替了。
现在清楚各种区别了吧,但是还有一个问题。也就是说,在处理多维数据时,什么时候该选择何种算法?这个问题很重要,因为若是数据维度大于三,你就找不到简单的方法来可视化地呈现数据。
原文链接:Logistic Regression Vs Decision Trees Vs SVM: Part I
(译者/赵屹华 审校/刘帝伟、朱正贵 责编/周建丁)
作者:赵屹华
版权声明:
本网站所有注明“来源:梅斯医学”或“来源:MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明“来源:梅斯医学”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言




收藏
77
#logistic回归#
34
#Logistic#
44
#支持向量机#
32
看不懂
131